Publications
[1] Yan Tai*, Weichen Fan*, Zhao Zhang, Ziwei Liu. (2024). Link-Context Learning For Multimodal LLMs. CVPR 2024. [paper][code] 
[2] Weichen Fan*, Jinghuan Chen*, Ziwei Liu. (2023). Hierarchy Flow For High-Fidelity Image-to-Image Translation. Proceedings of the TPAMI. [paper][code] 
[3] H. Gao*, W. Fan*, L. Qiu, X. Yang, Z. Li, X. Zuo, Y. Li, H. Ren, “SAVAnet: Surgical action-driven visual attention network for autonomous endoscope control”, IEEE Transactions on Automation Science & Engineering (T-ASE), 2022. [paper] 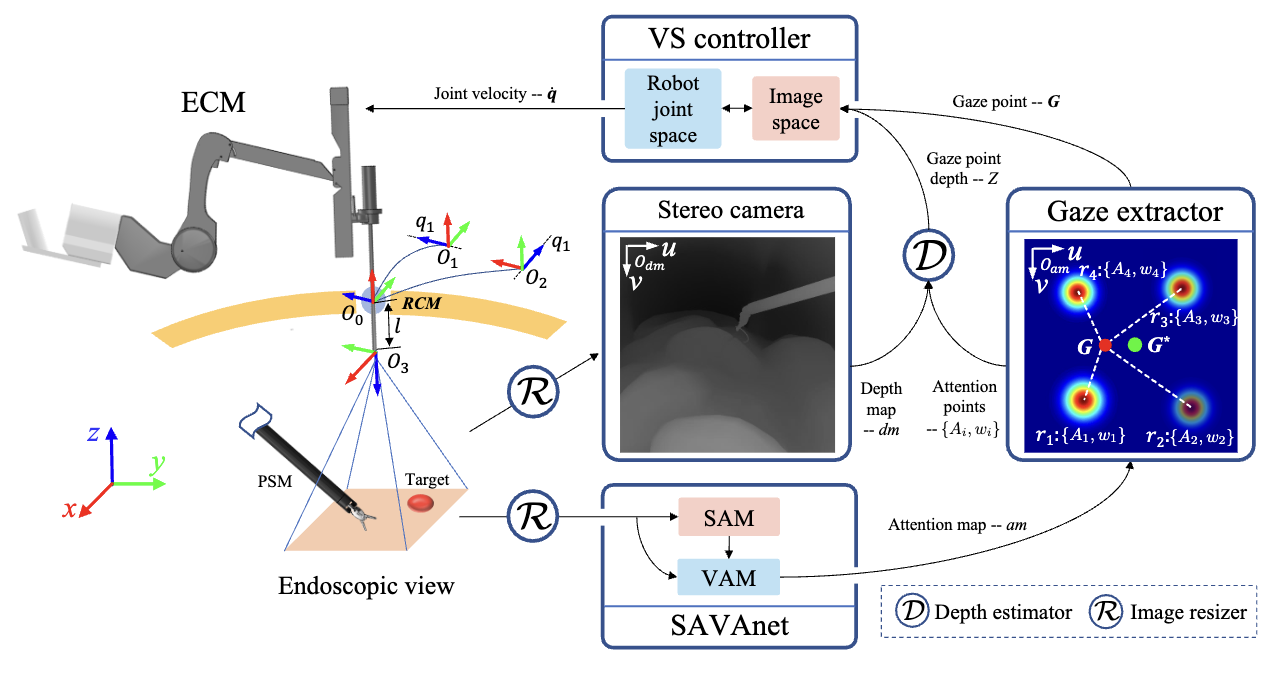
In this work, we learnt from the surgeons’ visual attention mechanism and propose a novel network called SAVAnet to predict visual attention with action guidance. Additionally, we implemented the SAVAnet on a da Vinci simulator to execute the autonomous endoscope control.